

Autores: Bianca Lahm Gomes e Kame Haung Zhu
Imaginemos um cenário no qual as máquinas não apenas processam informações, mas também têm a capacidade de aprender com experiências passadas e simular o comportamento humano: “estamos agora na fase inicial de outra mudança profunda, a era da inteligência artificial (IA)”, afirmou Bill Gates em seu blog pessoal.
À medida que a IA progride, as redes neurais emergem como protagonistas nessa revolução, redesenhando completamente a maneira pela qual os computadores geram conhecimento. Um exemplo desses avanços é o ChatGPT, trazendo muitas incertezas para leigos sobre seus limites e suas capacidades.
No Centro de Tecnologias Aplicadas (TA.DT), temos competências para resolver desafios empresariais por meio de projetos que empregam aprendizado de máquina (machine learning) e aprendizado profundo (deep learning), citando como exemplos de tais desafios detecção de fraudes, predição para séries temporais, detecção, classificação e segmentação de objetos em imagens, análise de sentimentos, monitoramento de pessoas, entre outros.
Embora os modelos de inteligência artificial não reproduzam completamente a complexidade humana, eles automatizam processos com alta precisão. Por isso, neste post, iremos explorar o que são redes neurais e como elas aprendem, para desmistificar algumas ideias associadas a elas, mostrando de fato como ocorre o processo de aprendizado, proporcionando assim um aprofundamento sobre o tema.
O que são redes neurais?
Redes Neurais Artificiais (RNA) são modelos de computação inspirados no sistema nervoso humano, constituídas de neurônios artificiais, esses se enquadram como modelos de aprendizado de máquina ou modelos de aprendizado profundo.
Uma RNA recebe um conjunto grande de informações completas sobre um determinado escopo que se deseja prever ou gerar informação, esses dados, que o modelo processa e produz saídas.
O objetivo principal de uma rede neural é aprender a relação entre os dados por meio de uma série de operações matemáticas e estatísticas. Contudo, para alcançar essas operações, foram necessários anos de pesquisa e testes que até hoje permeiam em serem validados.
Como surgiram as redes neurais
A trajetória teve início em 1943 com o artigo de McCulloch e Pitts, que introduziu o conceito de neurônio artificial. Os primeiros perceptrons (rede neural de camada única) surgiram na década de 1950, sendo incapazes de lidar com desafios mais complexos. Ao longo das décadas subsequentes, vários estudos foram realizados para aprimorar as capacidades das RNAs.
Na década de 1980, foi desenvolvido o algoritmo de retropropagação para treinar redes neurais de várias camadas. Mas foi a partir dos anos 2000, juntamente com o aumento da capacidade computacional, que grandes conjuntos de dados e avanços na teoria do treinamento de redes profundas permitiram que arquiteturas de redes neurais convolucional e recorrente ganhassem destaque como a base para a criação de outras arquiteturas subsequentes.
Em 2012, Alex Krizhevsky e sua equipe utilizaram uma arquitetura de rede neural convolucional conhecida como AlexNet para vencer a competição ImageNet Large Scale Visual Recognition Challenge (ILSVRC) com o conjunto de dados ImageNet, que continha aproximadamente 1,2 milhão de imagens rotuladas em mil classes diferentes.
O acontecimento foi um marco importante, pois na competição a equipe mostrou como escalonar as operações para aproveitar ao máximo as unidades de processamento gráfico (GPUs) no treinamento. Na sequência, houve um aumento substancial na disponibilidade de hardware, o que alavancou o aprendizado profundo.
A partir disso ocorreram avanços significativos, permitindo que as RNAs fossem treinadas em conjuntos de dados cada vez maiores, elevando assim sua capacidade de resolver problemas complexos de maneira mais sofisticada.
Nesse contexto evolutivo, com a quantidade de dados gerados diariamente pela humanidade, quem se destaca hoje popularmente é a arquitetura Transformer. Introduzida por Ashish Vaswani em 2017, ela trouxe melhorias significativas em relação às arquiteturas de rede neural recorrente (RNN) e é aplicada no modelo de rede neural Generative Pre-trained Transformer (GPT), que será detalhado em um dos tópicos mais adiante.
Humanos vs. redes neurais
No contexto de um aprendizado de máquina inspirado no cérebro humano, é possível dar ênfase às suas semelhanças e diferenças após interpretação das seguintes definições:
- O aprendizado humano é um processo pelo qual os indivíduos adquirem conhecimento, habilidades, atitudes ou comportamentos. É uma mudança relativamente permanente no comportamento, resultado da experiência ou da prática;
- O processo de aprendizado de máquina envolve a exposição do sistema a grandes volumes de dados, nos quais ela identifica padrões, realiza inferências e aprimora seu desempenho conforme é exposta a mais informações.
Semelhanças:
- Aprendizado com a experiência e a exposição a dados;
- Adaptar-se a novas situações;
- Aprender com erros e melhorar ao longo do tempo.
| Diferenças | |
| Humanos | Máquinas |
| Podem aprender uma ampla variedade de tarefas de forma flexível. | Geralmente projetadas para tarefas específicas e podem ter desempenho limitado fora do escopo de treinamento. |
| Podem explicar o raciocínio por trás de suas decisões e têm conceitos subjacentes. | No aprendizado por rede neural, não será possível mapear o processo de tomada de decisão. |
| Têm capacidade de aplicar conhecimentos aprendidos em uma ampla gama de contextos. | São especializadas em tarefas específicas para as quais foram treinadas. |
Funcionamento dos modelos de IAs
As redes neurais aprendem por meio do treinamento, elas têm arranjos entre milhares de neurônios chamados de unidades de processamento, onde são conectadas por canais de comunicação que estão associados a determinado peso.
Uma rede neural artificial pode ter centenas ou milhares de “neurônios” conectados. A seleção da arquitetura de conexão e técnica apropriada é crucial para resolver determinado tipo de problema.
Para problemas de visão computacional
Como classificação de imagens, detecção de objetos, rotulação de pixels, podemos utilizar a arquitetura Convolutional Neural Network (CNN), que é projetada para processar dados em formato de grade matricial.
A seguir, traremos uma figura abstrata de como ocorre o processamento das imagens por uma CNN para realizar o treinamento de detecção de objetos:
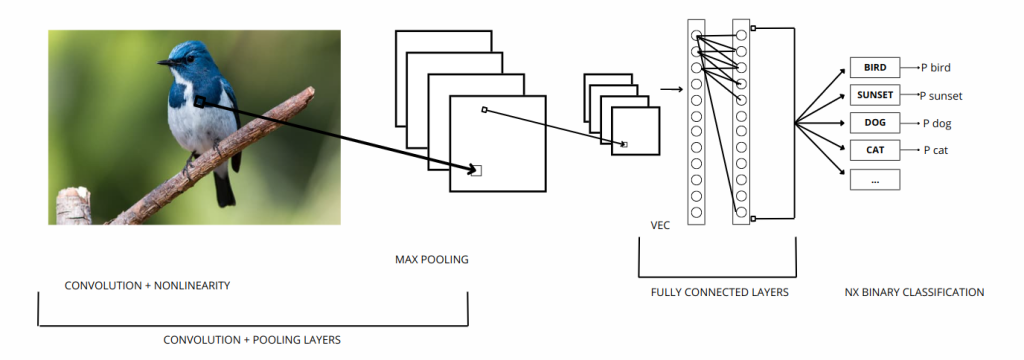
- Para cada pixel na imagem de entrada, codificamos a intensidade do pixel como o valor de um neurônio correspondente na camada de entrada.
- Aplicamos filtros convolucionais para capturar padrões locais.
- Esses filtros deslizam pela imagem, multiplicam os valores dos pixels pelos pesos correspondentes e somam esses produtos para criar um novo mapa de características.
- Esse mapa, então, é submetido a uma função de ativação que determina se o neurônio será ativado ou não.
- Após a camada convolucional, incluímos camadas de pooling (agrupamento) para reduzir a dimensionalidade e preservar as características mais importantes.
- Conectamos a rede a camadas totalmente conectadas, em que as características aprendidas são combinadas para realizar a tarefa final, como detecção de objetos, resultando na probabilidade de cada região pertencer ao objeto pelo qual foi treinado para identificar.
Ideias de aplicação: inspeção de qualidade industrial, monitoramento e automatização
Para problemas de processamento de linguagem natural
Um bom exemplo é a arquitetura Transformer, que representa um grande avanço e é aplicada nas redes neurais Generative Pre-trained Transformer (GPT – OpenAI) e Bidirectional Encoder Representations from Transformers (BERT – Google).
Essa arquitetura aprimora as criadas anteriormente com uma nova estruturação, na qual é possível paralelizar os problemas deixando o processo de treinamento e inferência mais rápido. Após o treinamento, esses modelos se tornam capazes de gerar textos coerentes e relevantes, como o texto gerado a seguir:
“Explique de forma muito resumida o funcionamento do GPT…
O GPT é um modelo de linguagem da OpenAI, construído com a arquitetura Transformer. Ele aprende padrões e significados em dados textuais durante o pré-treinamento, usando uma atenção contextual. Após essa fase, o GPT pode gerar texto coerente em resposta a entradas específicas, mostrando versatilidade em várias tarefas de linguagem natural.”.
De forma sucinta, podemos dizer que o GPT é inicialmente exposto a grandes volumes de texto para aprender padrões e relações semânticas entre palavras, como um pré-treino não supervisionado.
Logo, neurônios associados a conjuntos específicos de pesos processam sequências de palavras, com ajustes contínuos durante o treinamento para melhorar a previsão da próxima palavra. A rede otimiza milhões (ou bilhões) de parâmetros, contextualizando palavras para capturar nuances e contextos complexos durante o treinamento.
Ideias de aplicação: organização automática de documentos, tendências em redes sociais e notícias, identificação automática de conteúdo plagiado, identificação e extração de informações relevantes de documentos extensos.
Neurônios artificiais: conheça os cinco componentes
Por trás do aprendizado de redes neurais e suas arquiteturas, apresentadas anteriormente, temos o elemento central chamado neurônio artificial, que recebe o nome técnico de unidade de processamento. O funcionamento simplificado de uma unidade de processamento se divide em cinco componentes, que vamos detalhar a seguir:
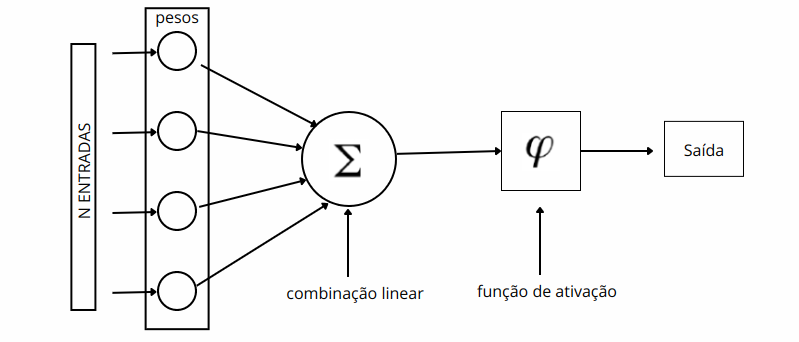
N Entradas: o neurônio recebe uma fração de informações de uma fonte de dados. Os inputs devem ser tratados para um formato específico, em que as informações devem estar em representação numérica em uma distribuição igualitária para todos os valores.
Por isso, sempre devemos enfatizar o tratamento de dados no processo de desenvolvimento de modelos de IA chamado de normalização.
Pesos: cada N entrada é multiplicada pelo seu peso correspondente. Os pesos são inicializados com parâmetros aleatórios e, ao decorrer do treinamento, são ajustáveis
Combinação linear: a soma ponderada das entradas multiplicadas pelos pesos é calculada. Isso é feito para combinar as entradas de acordo com a importância atribuída a cada uma delas pelos pesos. Eles representam a força da conexão entre os neurônios. Se o peso de uma entrada é alto, significa que essa entrada tem uma influência significativa na saída do neurônio.
Função de ativação: após a soma ponderada, o resultado passa por uma função de ativação. Essa função determina se o neurônio deve ser ativado (enviar um sinal) ou não, com base no resultado da soma ponderada.
Saída: a saída do neurônio é o resultado após a aplicação da função de ativação. Essa saída é então transmitida para outros neurônios na rede.
O aprendizado em uma rede neural envolve ajustar os pesos das entradas para formar conexões entre neurônios. O algoritmo de backpropagation faz ajustes contínuos nesses pesos durante o treinamento, minimizando a diferença entre a saída prevista e a desejada. Utilizando uma função de custo, ele utiliza o gradiente para indicar como os parâmetros devem ser ajustados. O resultado final é um conjunto de pesos que funciona como uma fórmula universal para prever novos exemplos do problema.
Enfim, o que esperar das redes neurais
As redes neurais não têm a finalidade de substituir a capacidade humana, mas sim aprimorá-la e complementá-la. Essa evolução tecnológica já foi observada em avanços passados, como no surgimento de computadores pessoais, a internet e a automação industrial, representando uma oportunidade para aprimorar processos empresariais.
O Itaipu Parquetec e o uso de redes neurais para melhorar a capacidade de trabalho
A Fundação Parque Tecnológico Itaipu vem realizando pesquisas em desenvolvimento para incorporar aos projetos o uso de redes neurais em diversas esferas de atuação.
No setor do agronegócio, as redes neurais realizam a identificação de pragas e doenças, promovendo práticas mais eficazes e sustentáveis.
Na gestão de energia, a manutenção preditiva é fundamentada na análise de dados de sensores para apoiar a eficiência operacional.
No âmbito do meio ambiente e território, a capacidade das redes neurais de analisar dados provenientes de drones e sensores permite um monitoramento ambiental mais preciso e em tempo real.
Além disso, em cidades inteligentes, a análise de padrões de tráfego facilita a gestão eficiente do fluxo veicular.
Na segurança pública, atuam na identificação de fraudes e no monitoramento de veículos e pessoas.
Por fim, na segurança de barragens, as redes neurais são aplicadas como ferramentas para o monitoramento estrutural, identificando padrões que alertam para potenciais problemas.
Adotar e integrar redes neurais em diferentes setores permite vislumbrarmos não apenas a automação de tarefas, mas também a melhoria nos processos e na qualidade das decisões tomadas.
Dessa forma, permitindo que os humanos gastem menos tempo com atividades repetitivas e morosas para serem mais produtivos no objetivo principal das suas demandas.
Tem perguntas ou deseja explorar oportunidades de aplicar redes neurais em seus projetos?
Estamos aqui para ajudar! Entre em contato conosco e descubra como podemos colaborar para impulsionar a inovação em sua empresa.
Envie suas dúvidas ou solicitações pelo nosso WhatsApp (45) 98822-6833 ou pelo e-mail centrodenegocios@itaipuparquetec.org.br.
Conheça outras ações do Itaupu Parquetec em nosso blog:
- Movimento Maker no Parque Tecnológico Itaipu: cultura que gera inovação
- Aplicação de tecnologia RFID para monitoramento de peixes no Canal da Piracema
- Explorando o potencial prático da visão computacional: o que é, aplicação e possibilidades
REFERÊNCIAS
André Carlos Ponce de Leon Ferreira. Neural Networks. Disponível em: https://sites.icmc.usp.br/andre/research/neural/. Acesso em: 4 dez. 2023.
Bill Gates. The risks of AI are real, but manageable. Disponível em: https://www.gatesnotes.com/The-risks-of-AI-are-real-but-manageable. Acesso em: 4 dez. 2023.
Brasil Escola. O que é aprendizagem? Disponível em: https://educador.brasilescola.uol.com.br/trabalho-docente/o-que-e-aprendizagem.htm. Acesso em: 4 dez. 2023
Data Science Academy. Introdução às Redes Neurais Convolucionais. Disponível em: https://www.deeplearningbook.com.br/introducao-as-redes-neurais-convolucionais/. Acesso em: 4 dez. 2023.
D2L. (s.d.). AlexNet. Dive into Deep Learning (Versão em Português). https://pt.d2l.ai/chapter_convolutional-modern/alexnet.html. Acesso em: 4 dez. 2023.
Erika G.L. Alves. Um breve estudo dos Transformers. Disponível em: https://erika-gl-alves.medium.com/um-breve-estudo-dos-transformers-6abbf1b77512. Acesso em: 4 dez. 2023.
IBM. Deep Learning. Disponível em: https://www.ibm.com/br-pt/topics/deep-learning. Acesso em: 4 dez. 2023.
NVIDIA. O que é um modelo Transformer? Disponível em: https://blog.nvidia.com.br/2022/04/19/o-que-e-um-modelo-transformer/. Acesso em: 4 dez. 2023.
Pinecone. (s.d.). ImageNet: The Definitive Guide. Disponível em: https://www.pinecone.io/learn/series/image-search/imagenet/. Acesso em: 4 dez. 2023.
TIBCO Software Inc. What is a Neural Network? Disponível em: https://www.spotfire.com/glossary/what-is-a-neural-network. Acesso em: 4 dez. 2023.
Zup. ChatGPT: entenda o que é e como funciona esse modelo de linguagem. Disponível em: https://www.zup.com.br/blog/chatgpt. Acesso em: 4 dez. 2023.